|
Chamblon Systems Inc. |
TerminologyExtractor |
|
[ Home ] [ TerminologyExtractor ] [ Quant ] [ Contact us ] [ Order ] [ How it works ] [ Download page ] |
|
Version 3.0 main features ·
Extraction
of words and collocations from Microsoft Word, RTF, HTML and
plain text documents. ·
Determines
frequencies. ·
Keywords
in context (KWIC) available on the main window. ·
On-line
sorting of terms by frequency and alphabetically. ·
Term
filter that allows a view of only the terms that contain a specific
string. ·
Searching of terms in all documents. Source
document names are included in search results. ·
Possibility
to export sorted term lists and search results. ·
Support
for Word for Windows XP. ·
Processes
all documents at the same time. No need to cut and paste smaller
documents together into one single large one before extracting terminology! You
can request a fully functional evaluation version of TerminologyExtractor 3.0
by e-mailing us at info@chamblon.com. Click
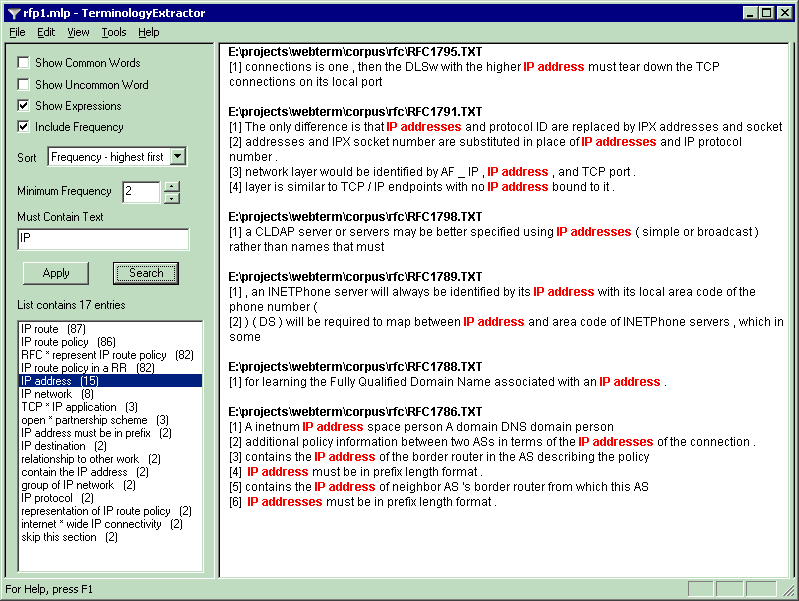
here to view a screen shot of version 3.0! You
may also want to take a look at the documentation
(help file). Description TerminologyExtractor is a tool that extracts word and
collocation lists, with frequencies, from Microsoft Word document, HTML,
Rich-Text Format and plain text files. TerminologyExtractor uses a number of
features and algorithms to provide the best possible output. For example,
when processing English and French texts, it uses the root form of each word,
i.e. it transforms plurals and conjugated verbs into singulars and
infinitves. It also uses lists of control words (pronouns, articles,
prepositions, etc.) to avoid collocations such as "of the" and
"I have". Also, all acronyms and proper nouns are kept in their
original form; no changes are made to uppercase and lowercase letters. One of the main features of TerminologyExtractor is that
it differentiates between words and non-words. TerminologyExtractor marks a
string as "word" if it is found in its dictionary. Otherwise, the
string is marked as "non-word". After TerminologyExtractor has
processed a set of documents, the non-word list contains abreviations, proper
nouns, misspelled words and words that are very specific to the domain of the
text. These can therefore be immediately spotted without having to manually
go through a long list of words. The collocation lists produced byTerminologyExtractor
contain all sequences of words and non-words that appear more than once in
the text. A special algorithm allows it to see collocations that appear
within longer collocations. For example, in a text about law you may find the
terms "justice system" and "criminal justice system".
These terms will both appear in the collocation list with their respective
frequency. Version 3.0 features an integrated KWIC module. The terms
(words, non-words and collocations) identified by TerminologyExtractor are
displayed in a list. A filter can be applied to the list in order to display
only the terms that include a word or part of a word. Terms can then be
selected from the list and their context (i.e. the sentence segments in which
they occur) displayed in a window or saved to a file. Click here for a description
of how TerminologyExtractor works. Applications TerminologyExtractor can be applied in many areas. They
include: Translation Quickly
extract terminology from a complete set of documents to speed up translation. Technical
writing Establish
the list of terms that everyone in the company should use. Identify terms
that are used inconsistently across a set of documents. Text
summarization Extract
the most commonly used words and collocations as well as the list of proper
nouns to provide an overview of what a text is about. Text
indexation Automatically
generate keyword lists, not only word lists. If you are
interested... ... Download a demo version of TerminologyExtractor. ... Look at example 1: output of TerminologyExtractor for
a technical article. ... Look at example 2: output of TerminologyExtractor for
an Internet RFC..
|
{kind=link}